Code of this article:
https://github.com/Kevin589981/PRML-ROBOT
Imitation learning offers a deceptively straightforward path to robotic manipulation: collect expert demonstrations, train a policy to mimic them, and deploy. Yet the critical question — how generalizable is the result? — exposes a fundamental tension. This post systematically examines what it truly takes to train robust imitation policies, from architecture choices and data distribution design to scalable data augmentation and visual sim-to-real transfer using MimicGen and Cosmos-Transfer.
1. The Core Challenge: Generalization in Imitation Learning
Imitation learning (IL), particularly Behavioral Cloning (BC), is a supervised regression framework: given expert state-action pairs $(s_t, a_t)$, train a policy $\pi_\theta$ to replicate them. Unlike reinforcement learning, there is no explicit reward signal to encode why certain behaviors are preferable — the policy purely mimics the demonstrations it has seen.
This simplicity is a double-edged sword. In controlled simulation with perfectly aligned demonstrations, BC can achieve near-perfect performance with minimal engineering. But the moment the deployment distribution diverges from training — different lighting, object poses, friction coefficients, or camera viewpoints — performance degrades sharply. The underlying reason is structural: BC lacks any mechanism for recovery or exploration, so compounding errors snowball unchecked once the agent leaves the training support.
Bridging this gap requires large-scale, diverse expert datasets. Yet data collection remains a major bottleneck, especially for complex systems involving multi-step manipulation, dual-arm coordination, or multi-fingered hands. Automated data generation in simulation thus provides a scalable alternative — provided we can also close the visual sim-to-real gap.
2. Environment and Task Design
2.1 PyBullet: Pick-and-Place
A 7-DoF Franka Emika Panda robotic arm is tasked with a single pick-and-place operation: grasp a cube at a randomized initial position and place it into a basket at a randomized target position. This deceptively simple task serves as the primary testbed for studying generalization factors — because precise spatial reasoning and robust visual localization are both required.
2.2 Isaac Sim: Multi-Step Cube Stacking
To evaluate more complex, long-horizon behavior, a harder three-cube stacking task was designed in Isaac Sim. The arm must pick and stack three cubes in a vertical sequence, requiring:
- Precise alignment and stable grasping at each step
- Sequential placement without disturbing previously placed cubes
- Multi-phase planning over a longer action horizon
Scripted expert generation is impractical here; human teleoperation via Apple Vision Pro was used instead.

Left: PyBullet pick-and-place environment. Right: Isaac Sim three-cube stacking environment.

3. Data Collection Strategy
3.1 Scripted Expert with Anthropomorphic Noise
For the PyBullet task, a 7-phase scripted expert policy was implemented:
(1) approach → (2) slow descent → (3) grasp → (4) lift → (5) transport → (6) slow descent to basket → (7) release
Crucially, perfect noise-free trajectories were deliberately avoided. To encourage the policy to learn robust closed-loop behavior rather than memorize open-loop movements, two noise sources were injected at every timestep:
- Gaussian noise: std = 0.002, applied with probability 0.3
- Ornstein–Uhlenbeck (OU) noise: regression coefficient $\alpha = 0.15$, diffusion $\sigma = 0.003$
Additionally, extensive initial-condition randomization was applied:
- Cube position range: $x \in [0.25, 0.65]$ m
- Basket position noise: $\pm 8$ cm in the x-axis (
basket_pos_x_noise = 0.08)
This forces the policy to rely on visual localization of the basket rather than hardcoded displacement vectors, substantially enhancing spatial generalization.
3.2 Apple Vision Pro Teleoperation
For the stacking task in Isaac Sim, hand pose data (26-DoF per hand) was captured via OpenXR tracking, then retargeted to the robot’s 7-DoF joint space via inverse kinematics (IK). The three cubes’ initial positions were randomized within a $0.2 \times 0.2$ m area to introduce meaningful variability in relative placements and grasp sequences.
The picture shows my collaborator
Qiu Qiming

Data collection via Apple Vision Pro teleoperation.

Complete pipeline: Vision Pro hand tracking → OpenXR → coordinate transformation & kinematic retargeting → smooth joint commands for Franka Panda arm.
4. Policy Architecture
4.1 Observation Spaces
Two distinct input modalities are compared:
Privileged State Space $\mathcal{O}{priv}$:
$$
\mathbf{s}{priv} = [\mathbf{q}, \dot{\mathbf{q}}, \mathbf{x}{ee}, \mathbf{x}{obj}^{ee}, \mathbf{x}{target}^{ee}] \in \mathbb{R}^{d{priv}}
$$
Ground-truth joint positions/velocities plus relative object and target positions with respect to the end-effector. Fully observable and Markovian.
Visual Observation Space $\mathcal{O}{vis}$:
$$
\mathbf{o}{vis} = [\mathbf{I}{front}, \mathbf{I}{wrist}, \mathbf{p}_{proprio}]
$$
Stacked RGB-D images $\mathbf{I} \in \mathbb{R}^{4 \times 112 \times 112}$ from two camera views plus proprioceptive data. Critically, no ground-truth object coordinates are provided — the policy must localize objects purely from pixels.
4.2 MLP-Base (Privileged Agent)
Since $\mathcal{O}_{priv}$ is Markovian, a deep Residual MLP without temporal memory suffices. Architecture: input projection → 6 Residual Blocks, each following:
Linear → LayerNorm → Mish → Dropout(0.1) → Linear → LayerNorm
The relative position vector $(p_{obj} - p_{ee})$ at each timestep uniquely determines the next optimal action, rendering LSTM-style memory unnecessary.
4.3 Vision-Final (Visuomotor Agent)
To handle high-dimensional RGB-D inputs and partial observability, a Recurrent Convolutional Network with three components is designed:
1. Visual Encoder (ResNet-18 + Spatial Softmax)
A modified ResNet-18 backbone accepts 4-channel RGB-D input (depth channel initialized via mean-averaging of RGB weights). The final Layer4 is removed to preserve spatial resolution; a projection layer reduces channels from 256 to $K=64$.
A Spatial Softmax layer then computes expected 2D keypoint coordinates for each feature map $k$:
$$(\mu_{x_k}, \mu_{y_k}) = \sum_{i,j} (i, j) \cdot \text{Softmax}(\mathbf{F}k){ij}$$
This compresses the visual representation into $\mathbf{z}_{vis} \in \mathbb{R}^{2 \times K \times 2}$ (2 cameras × 64 keypoints × 2D coordinates), encoding where objects are geometrically rather than what pixels look like — a key enabler of implicit visual servoing.
2. Temporal Aggregation (LSTM)
Visual features $\mathbf{z}_{vis}$ are concatenated with proprioception $\mathbf{p}_t$ and fed into a 2-layer LSTM with hidden size 512. Without the Markov property, the LSTM serves as a state estimator: it integrates history to denoise perception, smooth execution, and implicitly model phase transitions.
3. Multitask Heads
Two parallel output heads:
- Action Head: Predicts end-effector delta $\Delta \mathbf{x} \in \mathbb{R}^3$ and gripper action $a_{grip} \in [0,1]$
- Phase Head (Auxiliary): Predicts current sub-task phase $p_{phase} \in {1…7}$
The composite loss:
$$
\mathcal{L}{total} = \lambda{pos} \mathcal{L}{Huber}(\Delta \mathbf{x}, \Delta \hat{\mathbf{x}}) + \lambda{grip} \mathcal{L}{BCE}(a, \hat{a}) + \lambda{phase} \mathcal{L}_{CE}(p, \hat{p})
$$
with $\lambda_{pos}=1.0$, $\lambda_{grip}=0.5$, $\lambda_{phase}=0.2$. Dense phase supervision forces the LSTM to explicitly model the logical structure of the task, preventing oscillation at critical boundaries (e.g., “almost grasped” vs. “grasped”).
5. Experimental Results
5.1 Architecture Comparison
| Model |
Architecture |
Resolution |
Input Space |
Aux. Task |
Success Rate |
| MLP-Base |
Residual MLP |
N/A |
$\mathcal{O}_{priv}$ |
— |
98.6% (500 runs) |
| Vision-A |
CNN-LSTM |
64×64 |
$\mathcal{O}{vis} + \mathbf{x}{obj}^{ee}$ |
— |
100.0% |
| Vision-B |
CNN-LSTM |
64×64 |
$\mathcal{O}_{vis}$ |
— |
47.4% |
| Vision-Final |
CNN-LSTM |
112×112 |
$\mathcal{O}_{vis}$ |
Phase Pred. |
84.8% (500 runs) |
Key insight: Vision-A achieves 100% by cheating — it injects ground-truth object coordinates into the visual policy. Removing this privileged leakage drops performance to 47.4%. The combination of higher resolution (112×112 vs 64×64) and dense phase supervision recovers to 84.8%.
5.2 Privileged MLP: Strengths and Brittleness
The MLP-Base establishes a near-perfect upper bound of 98.6% under ideal conditions, with:
- Perfect geometric invariance: 100% success across cube shapes (
box_cube, cylinder, triangular_prism), since privileged observation abstracts objects to centroid coordinates
- Physical robustness: No degradation across friction $\in [0.5, 5.0]$, mass scaling $\pm 50%$, or external pushes up to 5 N
However, it exhibits catastrophic stateless brittleness:
| Parameter |
Condition |
Success Rate |
| Sim Timestep |
240 Hz (training) |
100% |
| Sim Timestep |
480 Hz (OOD) |
0% |
| Action Noise |
$\sigma=0.000$ |
100% |
| Action Noise |
$\sigma=0.010$ |
0% |
| Height Offset |
+5 cm |
100% |
| Height Offset |
+10 cm |
0% |
The learned action $\Delta pos$ is time-dependent rather than velocity-based: halving $\Delta t$ halves effective velocity, causing timeouts. The stateless MLP cannot low-pass filter execution jitter. These failure modes underscore the necessity of temporal memory for real-world deployment.
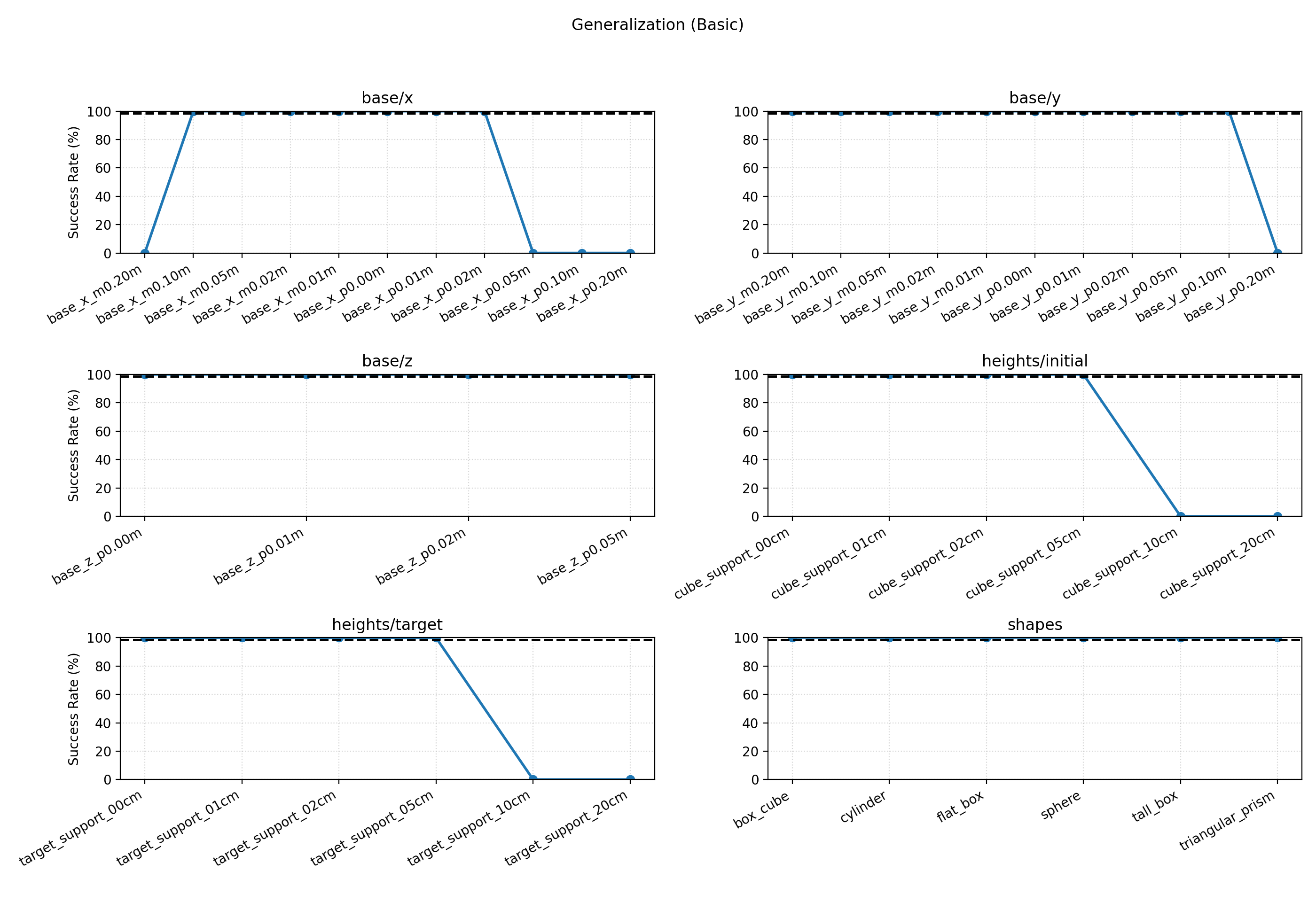
Basic generalization evaluation of MLP-Base across spatial variations. The policy shows strong geometric invariance but fails at hard spatial boundaries (e.g., height +10 cm).
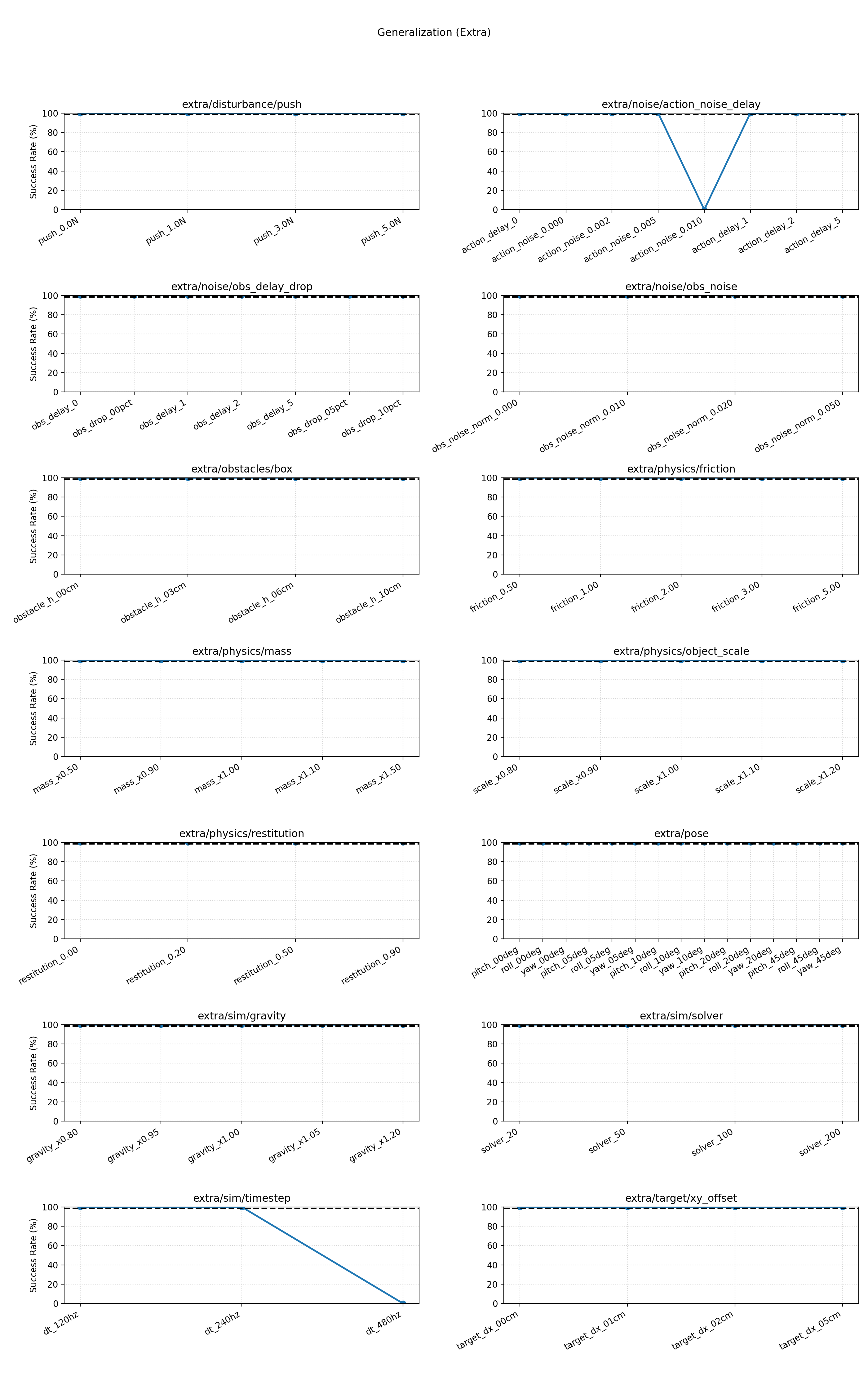
Full sweep of 12 robustness dimensions. Note the sharp drop-off in timestep and action_noise subplots — characteristic of stateless reactive control.
5.3 Vision-Final: Perceptual Resilience and Fragility
The vision policy achieves 84.8% success in fully randomized environments, showing impressive perceptual resilience:
- Camera pose noise (up to 5 cm): graceful degradation from ~86% to ~65% — Spatial Softmax enables implicit visual servoing rather than pixel memorization
- Basket position noise (±16 cm): >80% success, directly attributable to training-time basket randomization
- Friction (coefficient > 1.0): stable ~88% performance
Yet it exhibits sharp vulnerability in two regimes:
- Spatial OOD extrapolation: success drops linearly to ~50% when initial cube area doubles beyond training range — perspective distortion degrades ResNet spatial features at distribution edges
- Action execution noise: catastrophic failure at very low noise levels ($\sigma=0.002 \rightarrow 30%$; $\sigma=0.005 \rightarrow \sim10%$), far more sensitive than the privileged baseline. High-frequency jitter causes motion blur, feature jumps, and LSTM hidden-state divergence, trapping the arm in oscillatory behaviors
This highlights the fundamental challenge of end-to-end visual control: achieving temporal stability under inherently noisy and ambiguous perception.
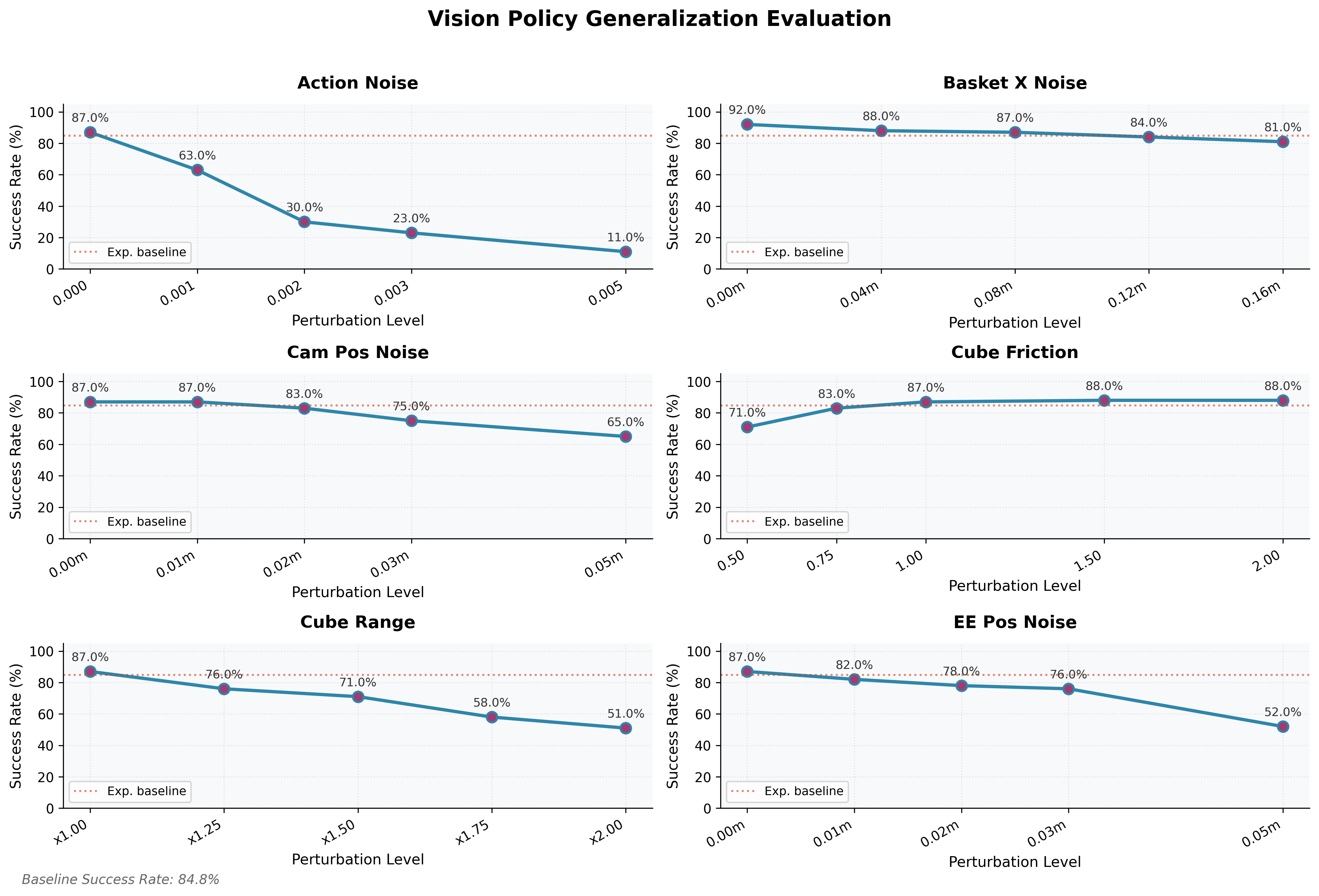
Success rates under varying degrees of perturbation across six dimensions. Strong robustness to visual noise and friction, but near-linear degradation with spatial OOD shift and extreme sensitivity to action execution noise.
5.4 Training Distribution vs. Generalization Capability
A controlled study with 100 demonstrations per condition reveals three distinct behaviors:
Coverage-Dependent Generalization (Cube Range):
Positive correlation between training distribution width and performance. Training on 25% of the full cube range → near-zero success (4.0%) on the hard evaluation set. The model cannot extrapolate to OOD spatial positions; coverage must encompass the test domain.
Stability-Inducing Generalization (Basket X Noise):
Counter-intuitively, less randomization improves test performance under data scarcity. Training with full noise → 33.0% success; training at 25% noise level → 58.0%. Under extreme data constraints, high variance prevents convergence on stable visual representations.
The “Sweet Spot” for Closed-Loop Correction (Reset EE Init Noise):
Performance peaks at 20mm noise (71.0%). Too little noise (10mm) → open-loop overfitting, failing to correct large deviations. Too much (30mm) → data too sparse to converge. The 20mm setting is an optimal balance: enough perturbation to induce closed-loop visual servoing without overwhelming model capacity.
Takeaway: Maximizing training randomization is not always optimal. Effective generalization requires balancing domain coverage with signal learnability, especially under data scarcity.
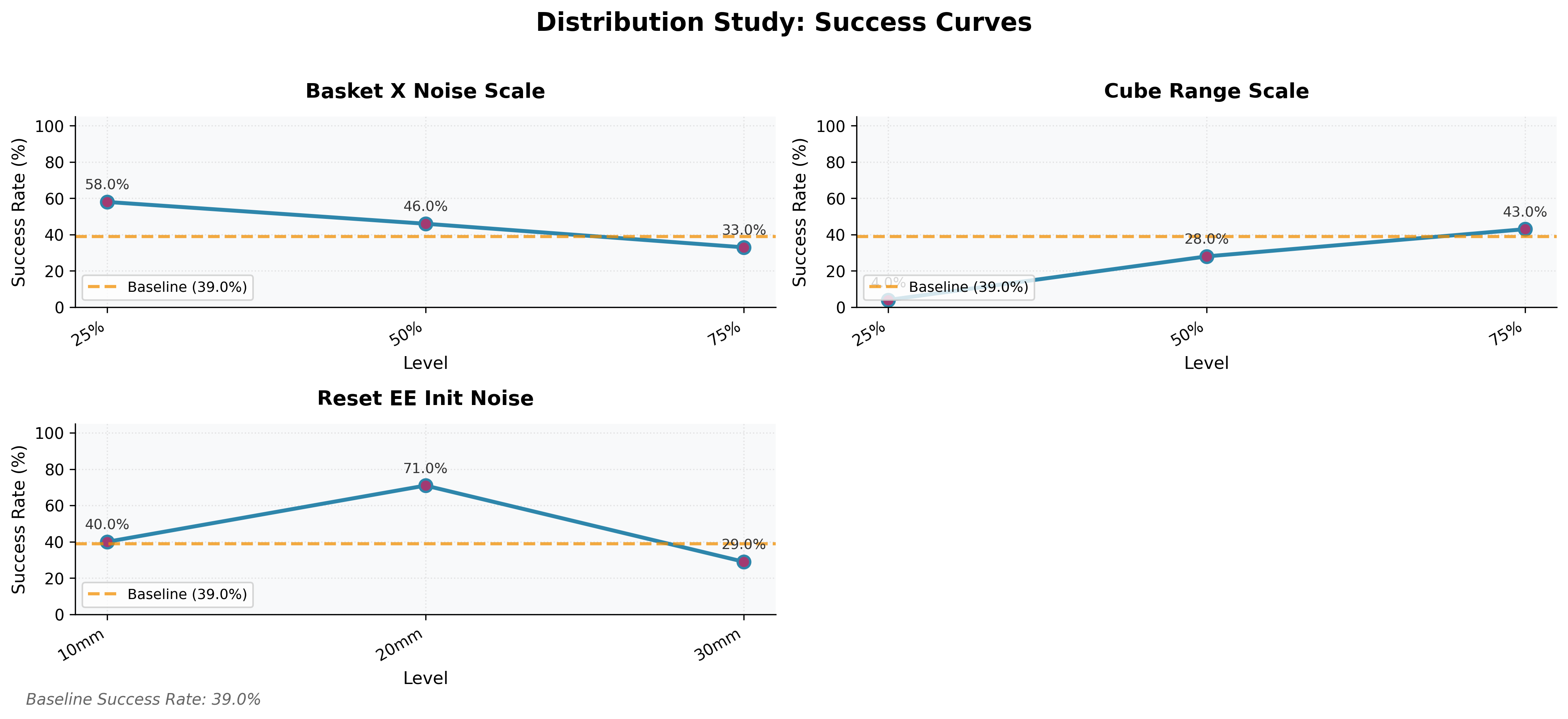
Success rates on the fixed “Hard” baseline when trained on datasets with varying randomization scales (100 demos each). Top left: inverse scaling in basket noise. Top right: direct scaling in spatial range. Bottom: the 20mm sweet spot for initial condition noise.
6. Scalable Data Augmentation Pipeline
6.1 MimicGen: Geometric Trajectory Augmentation
Starting from only 10 human teleoperated demonstrations for the stacking task, a MimicGen-inspired augmentation pipeline expands them to thousands:
- Key-Frame Extraction: Segment each demonstration into semantically meaningful subtasks; randomly sample anchor key frames per subtask
- Interpolated Trajectory Construction: Cubic spline interpolation between key frames with segment-wise Gaussian perturbation
- IK Re-solving: Re-solve end-effector trajectories via IK to guarantee kinematic validity; discard infeasible sequences
- Hand Action Replay: Replay gripper commands exactly at corresponding key frames to avoid grasp distortions
On an NVIDIA RTX 4090, 1000 augmented trajectories were generated from 10 source demonstrations in ~1 hour. Generation success rate (kinematically valid): 72.3%.
Scaling results on the stacking task:
| Training Dataset |
Trajectories |
Success Rate |
| MimicGen 1k |
1,000 |
60.0% |
| MimicGen 2k |
2,000 |
97.0% |
Doubling augmented data from 1k to 2k raises success from 60% to 97% — a striking demonstration of data volume’s role in imitation learning for contact-rich, multi-step tasks. Even synthetically interpolated trajectories provide meaningful distributional coverage.
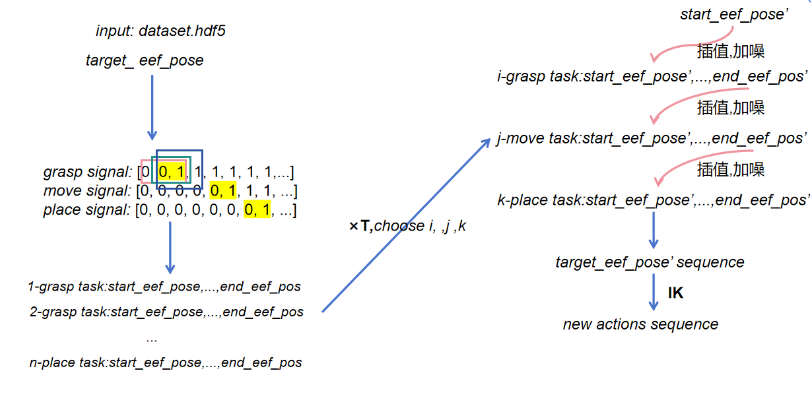
MimicGen trajectory augmentation: key-frame extraction, cubic spline interpolation, IK re-solving, and gripper action replay.
6.2 Cosmos-Transfer: Visual Domain Randomization
To close the perceptual sim-to-real gap, Cosmos-Transfer 1.0 (NVIDIA, 7B parameters) was applied. It is a diffusion-based multimodal controllable world generator that takes multiple conditional inputs — RGB video, semantic segmentation masks, and depth maps — and generates photorealistic video sequences conditioned on these modalities.
For each control branch $i$ and diffusion block $l$, intermediate activations $h_l^i$ are modulated by the corresponding adaptive spatiotemporal control map $w_l^i \in \mathbb{R}^{H \times W \times T \times N}$. The contribution to the main branch is:
$$
\text{output}_l = w_l^i \cdot h_l^i
$$
This adaptive fusion allows the model to dynamically emphasize the most informative modality in different spatial regions and timesteps, enabling fine-grained appearance stylization while preserving the underlying robot motion and scene geometry.
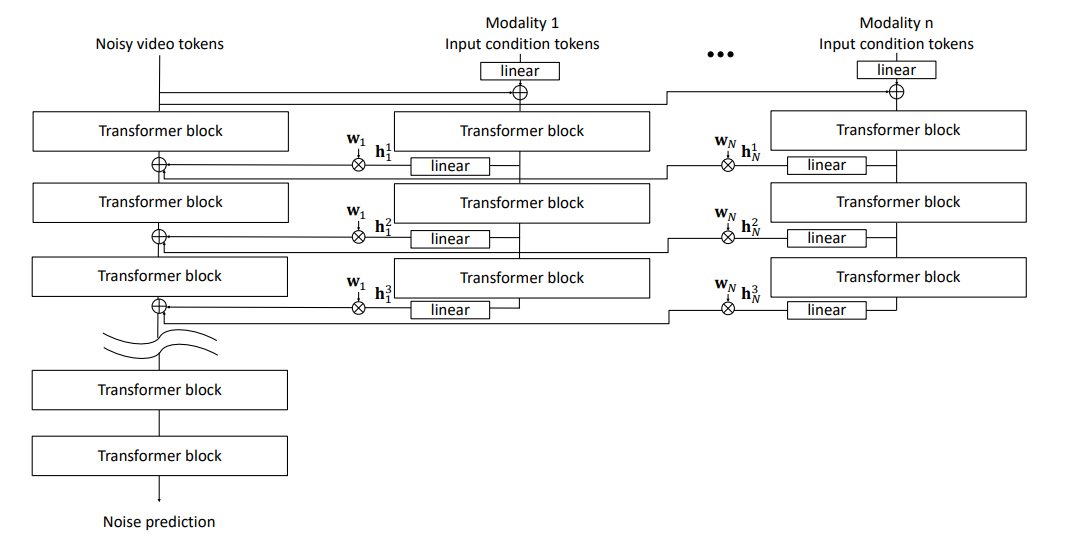
Cosmos-Transfer1 contains multiple ControlNet branches to extract control information from different modality inputs (segmentation, depth, edge), enabling adaptive multimodal world generation.
Qualitative results demonstrate successful transfer of: indoor/outdoor lighting, surface textures (wood, metal, plastic), background scenes, and rendering artifacts — all while keeping cube positions and robot trajectories intact.
| RGB Input |
Depth |
Segmentation |
Stylized Output |
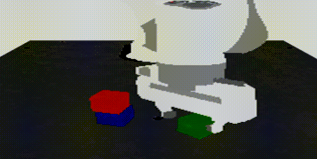 |
 |
 |
 |
Multimodal conditioning inputs (RGB, Depth, Segmentation) from one Isaac Sim frame, and the corresponding Cosmos-Transfer stylized output preserving robot motion while transferring photorealistic appearance.
Limitation: At 7B parameters, generating a single 10–20 second trajectory clip requires ~20 minutes on an RTX 4090. Full quantitative evaluation was beyond project scope. This remains a key bottleneck for large-scale sim-to-real pipelines.
7. Discussion: What Imitation Learning Reveals
The privileged $\to$ visual performance gap (98.6% vs 84.8%) is not a model capacity problem — it reflects a fundamental information asymmetry. Privileged observation is Markovian: the current state uniquely determines the optimal action, and memory-free reactive control suffices. Visual observation lacks the Markov property: occlusion, lighting variation, and perceptual ambiguity require history integration, model-based filtering, and higher execution precision.
The techniques that produced real gains:
- High-resolution inputs (112×112 vs 64×64): more spatial information for Spatial Softmax keypoint extraction
- Spatial Softmax: geometric feature extraction invariant to appearance, not memorizing pixel values
- Dense phase supervision: LSTM learns the task’s logical structure, not just reactive mapping
- Training-time randomization: prevents memorization of fixed configurations
- Geometric data augmentation (MimicGen): scalable path to diverse demonstration coverage
Persistent challenges that remain open:
- Spatial OOD extrapolation: IL cannot generalize beyond demonstration coverage — no reward signal guides recovery
- Action execution noise sensitivity: visual feedback latency amplifies high-frequency jitter into irreversible state divergence
- Compute cost of visual sim-to-real: world-model-based stylization is qualitatively promising but inference-limited at current scale
8. Conclusion
This work answers the deceptively simple question — “How difficult is it to train a robotic arm to do imitation learning in simulation?” — with a precise empirical answer: it may seem easy to train, but improving generalization remains a fundamental challenge.
Even on a simple pick-and-place task, modest distribution shifts cause sharp degradation in vision-based policies. The pipeline from 10 human demonstrations to a 97% success rate on a complex stacking task — via MimicGen augmentation — demonstrates that the data bottleneck can be partially overcome through geometric interpolation. World-model-based visual stylization (Cosmos-Transfer) holds great promise for closing the perceptual gap, pending inference efficiency improvements.
Future directions likely lie in:
- Diffusion Transformers (DiT): better out-of-distribution generalization over CNN-LSTM pipelines for complex demonstrations
- Hybrid IL + RL fine-tuning: imitation pre-training provides a good initialization; limited online RL provides recovery mechanisms
- Scaling world-model generation: orders-of-magnitude more diverse visual environments at lower inference cost
These small-scale experiments on seemingly simple tasks serve as a microcosm of embodied intelligence: achieving reliable, adaptive behavior in the physical world remains one of the most profound open problems in robotics.
延伸阅读
- [DexMimicGen]: Extends MimicGen to dexterous manipulation with multi-fingered hands via online simulation-based verification of generated trajectories
- [Diffusion Policy]: Replaces BC’s MSE regression with a diffusion process over actions, substantially improving multi-modal behavior and OOD generalization
- [MimicGen原论文]: Deep dive into the subtask decomposition and interpolation mechanics behind geometric trajectory augmentation